This blogpost contains a long Twitter thread on input parsers. I thought I'd copy the thread here as a blogpost.
I am spending far too long on this chapter on "parsers". It's this huge gaping hole in Computer Science where academics don't realize it's a thing. It's like physics missing one of Newton's laws, or medicine ignoring broken bones, or chemistry ignoring fluorine.
"Langsec" has the best model, but at the same time, it's a bit abstract ("input is a language that drives computation"), so I want to ease into it with practical examples for programmers.
Among the needed steps is to stamp out everything you were taught in C/C++ about pointer-arithmetic and overlaying internal packed structures onto external data. Big-endian vs. little-endian isn't confusing -- it's only made confusing because you were taught it wrongly.
Hmmm. I already see a problem with these tweets. People assume I mean "parsing programming languages", like in the Dragon book. Instead, I mean parsing all input, such as IP headers, PDF files, X.509 certificates, and so on.
This is why parsing is such a blindspot among academics. Instead of studying how to parse difficult input, they've instead designed input that's easy to parse. It's like doctors who study diseases that are easy to cure instead of studying the ones hard to cure.
Parsing DNS is a good example. In a DNS packet, a name appears many times. Therefore, a "name" appearing a second time can instead just point to the first instance. This is known as "DNS name compression". In this packet, "google.com" exists only once.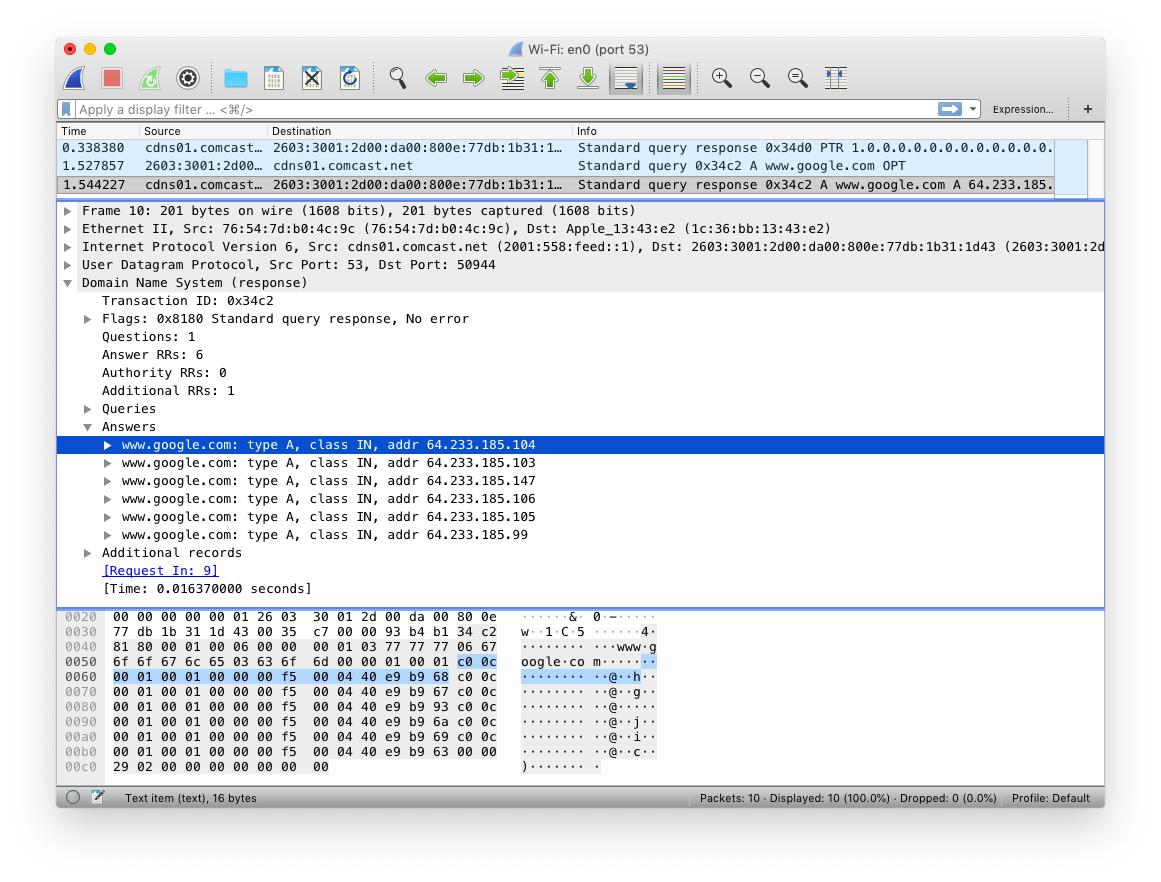
Any abstract model for "parsing" you come up with doesn't include this compression step. You avoid the difficult parts to focus on the easy parts. Yet, this DNS compression feature is a common source of parser errors.
For example, you can create an infinite loop in the parser as a name points to another name that points back again. Multiple CVE vulnerabilities are due to this parsing bug.
As this tweet describes, "regex" is "hope-for-the-best" parsing. This is how most programmers approach the topic. Instead of formally parsing things correctly, they parse things informally and incorrectly, "good enough" for their purposes.

Things designed to solve the parsing problem haven't, like XML, ASN.1, or JSON. First of all, different implementations parse the raw documents differently. Secondly, it's only the first step, with lots remaining to be parsed.

This is the enormous flaw of RPC or "Remote Procedure Call", that promised to formally parse everything so that the programmer didn't have to do it themselves. They could call remote functions the same as internal local ones with local data.
This lead to numerous exploits and worms of SunRPC on Unix systems at the end of the 1990s and exploits/worms of MS-RPC at the start of the 2000s. Because it's a fallacy: external data is still external data that needs to be parsed.
For example, the "Blaster" bug was because a Windows computer name can't exceed 16 characters. Since no internal code can generate longer names, internal code doesn't keep double-checking the length, but trusts that it'll never be more than 16 characters.
But then two internal components are on either side of RPC -- remote from each other, where a hacker can change the bytes to create a longer name. Then you have a buffer-overflow, as an internal component receives what it thinks is an internally generated name, but isn't.
This is a general problem: programmers don't know what's internal and what's external. That's the problem with industrial control systems, or cars. They define the local network as trustworthy and "internal" to the system, when it should instead be defined as "external".
In other words, the Jeep hackers went from the Internet into the car's entertainment system, and once there, were able to easily hack other components across the CAN bus, because systems treated input from the CAN bus as "internal" to the car, instead of "external" to the system.
Eventually we'll need to move to "memory safe" languages like Rust, because programmers can never trust a buffer size is what it claims to be. In the meanwhile, all C/C++ code needs to respect the same sort of boundary.
That means we need to pass around the buffer size along with the buffer in API calls. It means that we need to pretend our language is memory safe. That means no more pointer arithmetic, and no more overlaying internal packed structures on top of external data then byte-swapping.
I know, I know. When you learned about "htons()" and "ntohl()" in your Network Programming class, you had an epiphany about byte-order. But you didn't. It was wrong. You are wrong. They violate type safety. You need to stop using them.
Some jerk of a programmer working for BBN wrote these macros when adding TCP/IP to BSD in 1982 and we've suffered with them ever since. They were wrong then (RISC processors crash on unaligned integer access), and doubly wrong today (violates type safety).
You need to think of htons()/ntohl() macros are as obsolete as sprintf(), a function well-known for overflowing buffers because it has no ability to bounds-check, no concept of the length of a buffer it's writing into.
Pointer arithmetic is also wrong. You were taught that this is idiomatic C, and you should always program in a programming language's own idioms instead of using another programming language's idioms ("A Fortran programmer can program in Fortran using any language").
But pointer arithmetic isn't idiomatic C, it's idiotic C. Stop doing it. It leads to spaghetti code that really hard for programmers to reason with, and also hard for static analyzers to reason with.
As architects, we aren't building new castles. We spend most of our time working with existing castles, trying to add electricity, elevators, and bringing them up to safety code. That's our blindspot: architects only want to design new buildings.

Let's talk about C for a moment. The Internet is written in C. That's a roundabout way of stating that C predates the Internet. The C programming language was designed in an era were "external" data didn't really exist.
Sure, you had Baudot and ASCII, standard external representation of character sets. However, since computers weren't networked and "external" wasn't an issue, most computers had their own internal character set, like IBM's EBDIC.
You see a lot of HTTP code that compares the headers against strings like "GET" or "POST" or "Content-Type". This doesn't compile correctly on IBM mainframes, because you assumed the language knew it was ASCII, when in fact C doesn't, and it could be EBDIC.
Post-Internet languages (e.g. Java) gets rid of this nonsense. A string like "GET" in Java means ASCII (actually, Unicode). In other words, the letter "A" in Java is always 0x41, whereas in C it's only usually 0x41 but could be different if another charset is used.
Pre-internet, it was common to simply dump internal data structures to disk, because "internal" and "external" formats were always the same. The code that read from the disk was always the same as the code the wrote to the disk.
This meant there was no "parsing" involved. These days, files and network headers are generally read by different software than that which wrote them -- if only different versions of the software. So "parsing" is now a required step that didn't exist in pre-Internet times.
I'm reminded that in the early days, the C programming language existed in less than 12k of memory. My partial X.509 parser compiles to 14k. Computers weren't big enough for modern concepts of parsing.

Many want "provably correct" and "formal verification" of parsers. I'm not sure that's a thing. The problem we have is that the things we are parsing have no format definition, and thus no way to prove if they are correct.

You think they formally defined. But then you try to implement them, and then you get bug reports from users who send you input that isn't being parsed correctly, then you check the formal spec and realize it's unclear how the thing should be parsed.
And this applies even when it's YOU WHO WROTE THE SPEC. This is a problem that plagues Microsoft and the file/protocols they defined, realizing that when their code and specs disagree, it means the spec is wrong.
This also applies to Bitcoin. It doesn't matter what the spec says, it matters only what the Bitcoin core code executes. Changes to how the code parses input means a fork in the blockchain.
Even Satoshi (pbuh) failed at getting parsers right, which is why you can't have a Bitcoin parser that doesn't use Bitcoin core code directly.
That issue is "parser differentials", when two different parsers disagree. It's a far more important problem than people realize that my chapter on parsers will spend much time on.

This is another concept I'll have to spend much time on. Parsing was flexible in the early days (1970s/1980s) when getting any interoperability was a big accomplishment. Now parsers need to be brittle and reject ambiguous input.
In the past, programmers didn't know how to format stuff correctly, so your parser had to handle ambiguous input. But that mean how your popular parser handled input became part of the unwritten spec -- parts everyone else struggled with to be compatible.
Modern work, from HTML to XML to DNS now involves carefully deprecating past ambiguous parsing, forcing parsers to be much stricter, defining correct behavior as rejecting any ambiguity.
In other words, in the old thinking, the parser should recognize this a vote for Franken, because that's clearly the intent. In the new thinking, the parser should reject this input for not following the rules (two bubbles filled in).
I'm not including this in my chapter on "Parsers" only because it gets it own chapter on "State Machine Parsers".

Among the benefits of non-backtracking state-machine DFA parsers is that they don't require reassembly of fragments. Reassembly is the source of enormous scalability and performance problems. You can see examples of how they work in masscan:

Which brings me to a discussion of "premature optimizations", an unhelpful concept. Those who don't want to do state-machine parsers will cite this concept as a reason why you shouldn't do them, why you should worry about reassembly performance later.
On the other hand, prescriptions against premature optimization won't stop you from doing pointer-arithmetic or structure/integer overlays, because you will defend such approaches as improving the performance of a program. They don't, by the way.
Another unhelpful concept is the prescription against "magic numbers". Actually, they are appropriate for parsers. "ipver == 4" is often much better than "ipver == IPV4". If the source of a number is a separate spec, then defining the constant with a string has little benefit.
When I read the code, I have the specification (like the RFC) next to me. The code should match the spec, which often means magic numbers. If I have to hunt down things defined elsewhere, I get very annoyed, even in a good IDE where it's just a few clicks away.
Don't get me wrong. An enum {} of all possible values for a field, culled from multiple specifications and even non-standard vendor implementations, is also useful. The point is simply: don't get uptight about magic numbers.
(Sorry for the length of this tweet storm -- at this point I'm just writing down notes of everything that needs to go into this chapter, hoping people will discuss things so I get it right).
1 comment:
When you use PBUH, do you use it ironically? I can't ever tell your intention.
Post a Comment